
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- neural network
- 언어모델
- ML
- GPT
- Unsupervised Learning
- Machine Learning
- supervised ml
- 프롬프트 엔지니어링
- learning algorithms
- LLM
- 머신러닝
- Andrew Ng
- AI 트렌드
- Scikitlearn
- nlp
- 인공신경망
- llama
- 챗지피티
- Supervised Learning
- AI
- 딥러닝
- feature scaling
- Deep Learning
- feature engineering
- 인공지능
- bingai
- coursera
- Regression
- ChatGPT
- prompt
- Today
- Total
My Progress
[Supervised ML] The problem of overfitting / Regularization - 10 본문
[Supervised ML] The problem of overfitting / Regularization - 10
ghwangbo 2023. 8. 1. 17:501. Intuition
Regression Example
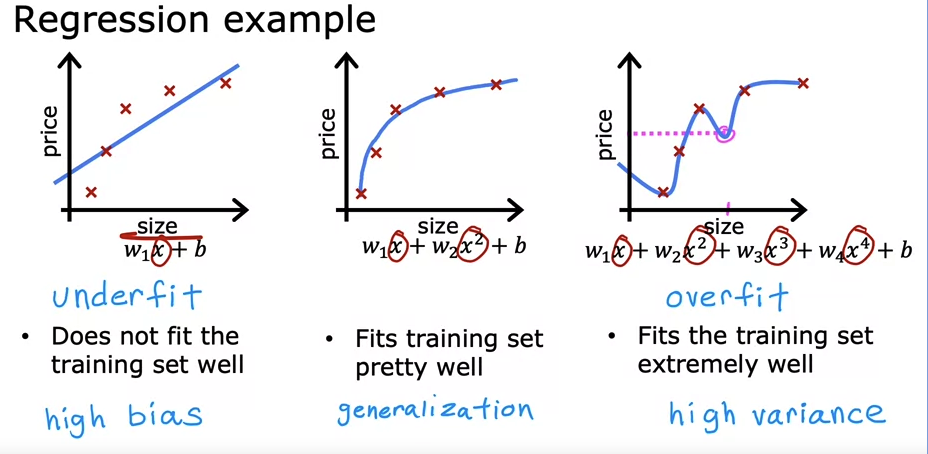
Underfit / High bias : does not fit the training set well
Overfit / High variance: Fits the training set extremely well
Generalization: Fits training set pretty well
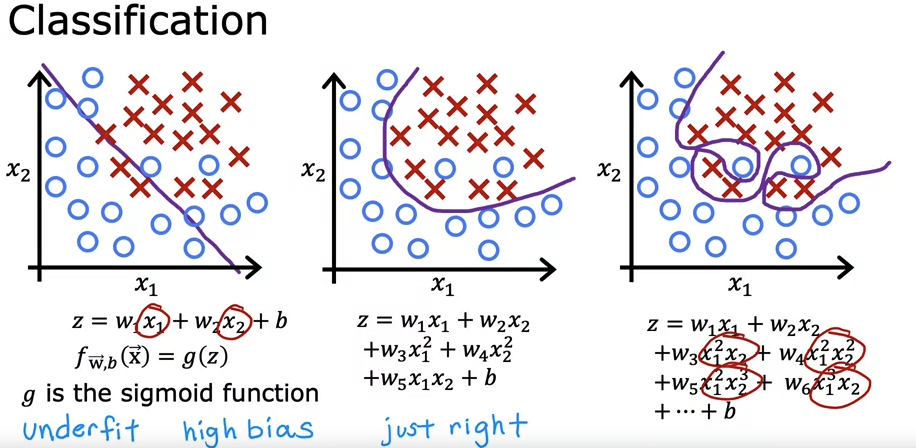
Even though overfitting example might have a high accuracy on the training set, it will not have a high accuracy for new test dataset.
2. Addressing overfitting
Option 1: Collecting more examples
By collecting more training examples, the function will be more generalized.
Option 2: Select features to include/exclude
Overfitting might occur by taking in too many features: wx1 + wx2 + wx3 .........
By selecting only necessary features(feature selection), we can generalize the function.
Option 3: Regularization
Reducing the size of parameteres w.
Rather than eliminating the feature, we can gently reduce the impact of the feature.
3. Regularization
3.1 Intuition

By setting w to a really small number, we can reduce the impact of our selected features.
How do we implement it in our cost function?
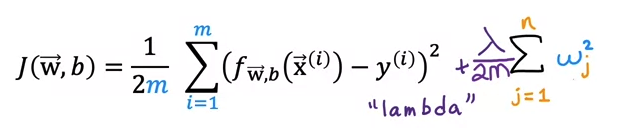
Lambda is a regularization parameter

In some cases, we penalize the impact of b. We add lambda/2m * b^2.
ex) When regularization term is really big, w will approach to 0.
3.2 Regularized Linear Regression
We will implement regularization term to our gradient descent formula in linear regression.
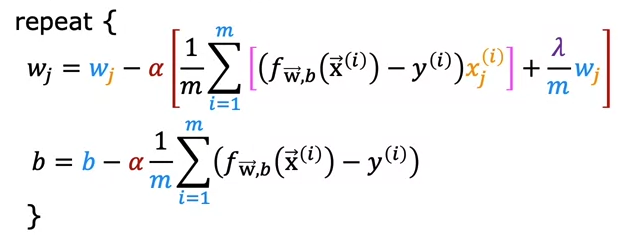
This is the gradient descent formula with regularization included.
3.3 Regularized Logistic Regression
Regularized Logistic Regression is the same as linear regression except for f(x) which uses the sigmoid function.
'AI > ML Specialization' 카테고리의 다른 글
| [Advanced Learning Algorithms] Neural Network - 1 (0) | 2023.08.03 |
|---|---|
| [Supervised ML] Review - 11 (0) | 2023.08.03 |
| [Supervised ML] Cost function/Gradient descent for logistic regression - 9 (0) | 2023.07.31 |
| [Supervised ML] Classification with logistic regression - 8 (1) | 2023.07.30 |
| [Supervised ML] Feature Engineering - 7 (0) | 2023.07.28 |



